
Load balancing as a Service (LBaaS) allows application teams to rapidly deploy load balancers, web application firewalls, API gateways, and other application delivery services.
Introduction
Load balancing as a Service (LBaaS) allows application teams to rapidly deploy load balancers, web application firewalls, API gateways, and other application delivery services.
Large organizations and Managed Service Providers have hundreds or thousands of application teams or tenants that must develop applications fast and efficiently. LBaaS is more effective than static infrastructure in terms of launching apps faster and providing secure and scalable access to customers. LBaaS can break down the silos typical in traditional IT and the long provisioning times that hold up service tickets.
In this blog post, we will discuss how a modern application delivery platform such as Snapt Nova enables LBaaS – allowing Platform Operations to manage self-service capabilities and delegate management to application teams. Centralized security measures allow operations and platform teams to apply governance and compliance. APIs and per-app services, on the other hand, enable application developers to rapidly build and tailor their end-to-end application delivery infrastructure.
What is Load Balancing as a Service?
The Load Balancer
Let’s recap load balancing…
Load balancing began in the 1990s to spread traffic across a network of hardware devices. Organizations sought to make it simpler for users to access applications on servers.
Hundreds of web servers simultaneously handle thousands of client requests while load balancers sit between the end-user and your servers, controlling this traffic.
The advancement of Application Delivery Controllers (ADCs) has enhanced load balancing and has become even more substantial. The Term ADCs encompass all application delivery services, mainly load balancers with the expanded capabilities of web application firewalls, API gateways, caching, and proxying.
They provide improved security and performance to customers to enhance application access during peak hours while mitigating the ever-increasing number of threats on the internet.
ADCs will, without a doubt, continue to be the core conduit and integration point for apps for a long time. The essential connection point to create efficient, smarter, and safer applications will also continue to adapt with modern IT infrastructure, where cloud and containers are more popular than ever before, and convergence of development and operations, or as we know it, DevOps.
as-a-service
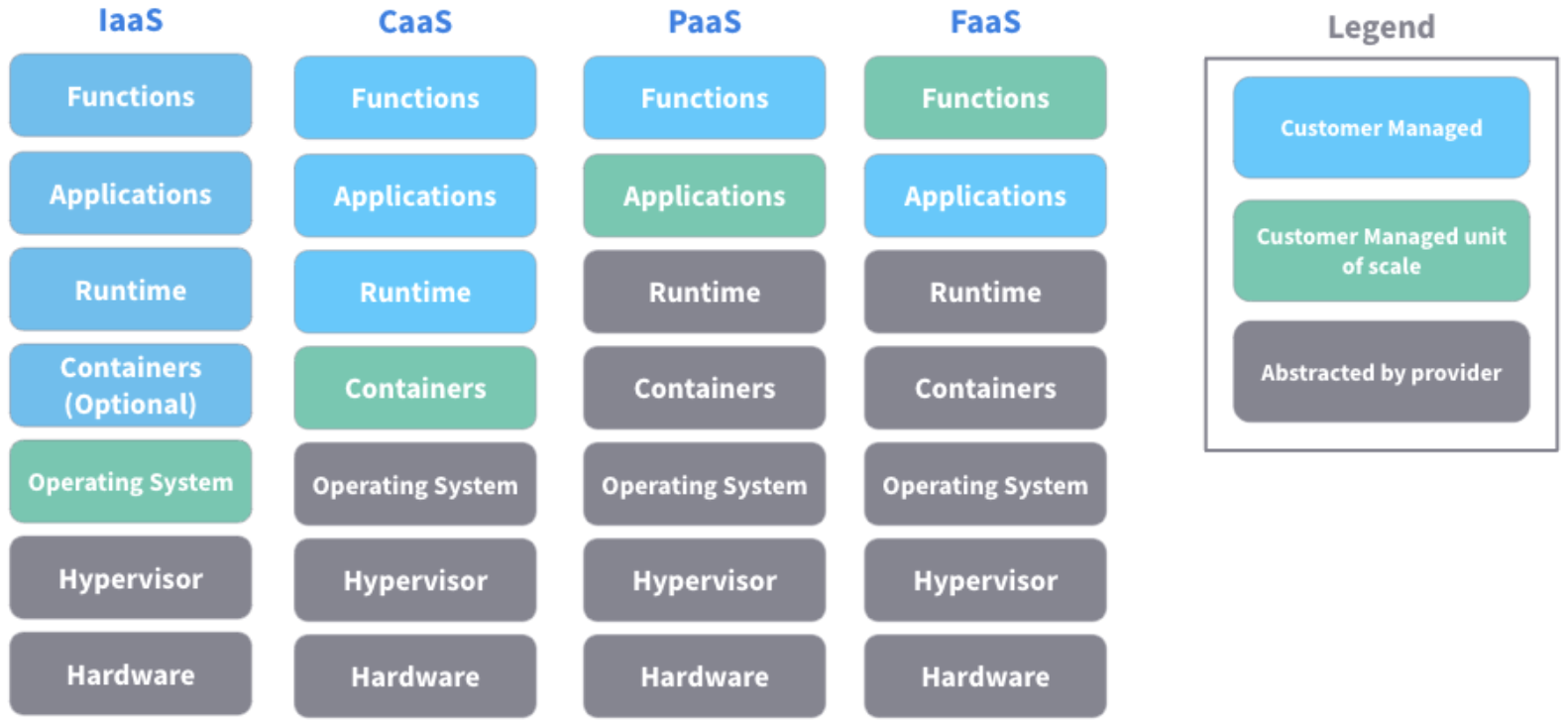
The term “as-a-Service” refers to delivering anything as a service over the internet. It acknowledges the many distinct items, solutions, and technologies that are integrated and supplied in an as-needed and self-service manner over a networked system, generally the internet.
There are a lot of as-a-Service examples, but the most common ones are Software as a Service (SaaS), Platform as a Service (PaaS), and Infrastructure as a Service (IaaS).
SaaS provides users with a wide range of software applications, such as Google Apps, Microsoft Office 365, and Salesforce.
Popular PaaS include Amazon Web Services (AWS) Elastic Beanstalk for long-running applications or AWS lambda for short-running code functions. Heroku, Google App Engine, and many more providers provide pre-configured virtual machines (VMs) and other application development and testing resources.
Organizations may use IaaS to deploy and set up virtual machines in a vendor’s data center and operate them remotely. Microsoft Azure, Google Compute Engine, and AWS Elastic Compute Cloud are examples of IaaS services.
There are many other examples of as-a-Service offerings. Storage as a Service (SaaS) delivers application, data, and backup storage systems in the cloud, whereas Database as a Service (DBaaS) gives clients access to a database platform through the cloud.
The pace at which cloud providers are adopting the as-a-Service (aaS) approach to delivering just about everything shows how companies worldwide are adopting this method. Heck, that’s why we’re seeing services like ransomware as a service!
What are the pros and cons of XaaS?
Many organizations choose the as-a-service model because it can save money and simplify IT infrastructure and operations costs.
With each new cloud service, an organization’s internal IT infrastructure may be reduced, resulting in fewer servers, hard drives, network switches, software installations, and other things. As-a-service means less physical overhead.
From an operations standpoint, the as-a-service model can alleviate the operations burden by delegating the end-user, tenant, or team to manage their own infrastructure and services in a self-service-like fashion. The as-a-service model abstracts several complex integrations “under the hood,” so to speak, and presents an abstracted view of managing application and networking infrastructure.
All this implies fewer Technology workers involved in maintaining the infrastructure in the physical data center or even the developers who maintain the application code. Empowering end-users also avoids the problem of bottlenecks created by the requirement of opening IT service management for changes, allowing IT professionals to focus on creating value, not other “busy work.”
Furthermore, an as-service model moves to utilize a third-party service rather than in-house technology and shifts many capital expenditures (Capex) to operational expenses (Opex) for the company.
Despite their benefits, XaaS services confront issues of resilience and internet dependability from time to time. Some companies also desire greater insight into their service provider’s infrastructure and environment to better assess service health and assume a more proactive role. Despite the abstractions of the as-a-service platform or service’s underlying engine, the quality of the compute and data plane performance is still critical
The Cloud-like Experience
The advent of cloud computing has given rise to a new way of thinking about software and services. Today, more and more software is delivered as “as-a-service,” meaning it is available over the Internet or through a mobile app. As a result, the term “as-a-service” is now interchangeable with “cloud-like.”
As more business and consumer services move to the cloud, the cloud-like experience has become the standard by which we evaluate even the most complex of services in terms of their user experience and consumption model.
For on-premises deployment, organizations desire a cloud-like approach that provides public cloud advantages like scalability, cost, flexibility, and administration while avoiding the risks or drawbacks of the public cloud.
What is LBaaS / ADCaaS?
The terms “load balancers” and “ADCs” are frequently used these days interchangeably, as are “Load Balancing as a Service” (LBaaS) and “Application Delivery Controller as a Service” (ADCaaS), additionally, it can be referred to as Software-Defined Load Balancing.
The core Load Balancing capabilities, such as routing, TLS termination, and health checks, are typically available on public cloud and private cloud infrastructure as built-in functions you can use optionally as needed. In contrast to Advanced Load Balancers designed to be independent of a platform, platform-centric “LBaaS” sacrifices many of the “bells and whistles” of a full-featured Load balancer in favor of a self-service configuring and on-demand provision model.
In the same way that ADCs imply more functions and capabilities than a Load Balancer, an ADCaaS implies the same thing in an as-a-service context when compared to LBaaS. ADCaaS adds more application services than just load balancing on demand, such as Firewall security features, Denial of service and bot detection, or performance capabilities like web content optimization or rate-limiting
Perhaps for simplicity or for its legacy name, We frequently hear the phrase “LBaaS” rather than “ADCaaS.” We’ll discuss later in this post that fact, most LBaaS or ADCaaS solutions provide merely basic Load Balancing features and so the term LBaaS is probably more appropriate than ADCaaS
LBaaS examples
- Public Cloud - AWS ELB/ALB/NLB (Single Public Cloud Solution)
- Private Cloud - Open Stack (a pluging for Self hosted cloud infrastructure)
- Multi-cloud - Snapt Nova, NGINX Controller and AVI Networks
What problems does LBaaS solve in the enterprise?
Problem: The Traditional ADC Model
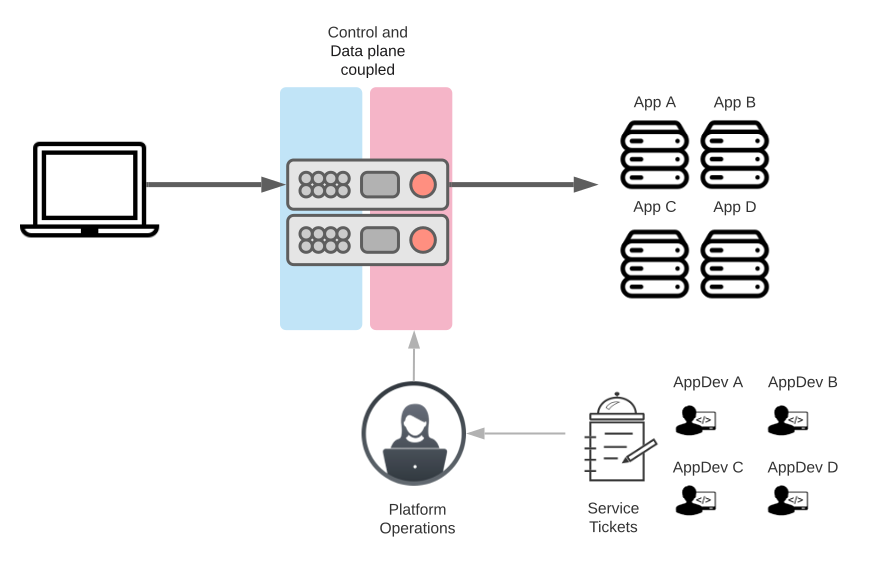
Traditional ADCs are stifling development and concentrating workloads on a single bottleneck. In a setting with hundreds or even thousands of apps, the traditional ADC model becomes a workload “bottleneck” with the potential to produce a large “blast radius” that can jeopardize your business.
Furthermore, the traditional ADC approach limits agile development methods that allow the rapid introduction of new features because they are typically heavyweight and monolithic appliances designed for the static data center and not dynamic platforms such as cloud and containers deployed as microservices.
Take the example of microservices, which are poorly suited for traditional ADCs. Microservices apps are made up of various services that require a lot of change and application delivery at breakneck speeds by many different app development teams. With each new update of the software, several modifications to ADCs are typically necessary, such as route changes, security policies, etc. The traditional ADC model supporting modern applications can result in continuous policy changes, which might severely strain ADCs and destabilize your application delivery and security. It also strains platform operations teams forced to make service updates during designated maintenance windows because of the burden of managing the delivery of many services.
Typical Characteristics of Traditional ADC
- Traditional ADCs are shared and multi-tenanted.
- Many applications and tenants are co-located on the same hardware or software virtual instance; Historically, this was done for management and Cost reasons.
- They are operational and performance bottlenecks that create a Large Blast radius in the event of a failure.
- Licensing by a traditional ADC vendor is cost-prohibitive, and so their customers avoid deploying the optional architecture and settle for large boxes in a High-availability pair configuration.
- The lack of decoupled control plane makes managing a large fleet of ADCs impractical, so they continue to stack workloads on the same devices.
- This model typically results in Application teams opening tickets for NetOps teams to execute changes on ADC.
A Better Model: Micro ADC Model
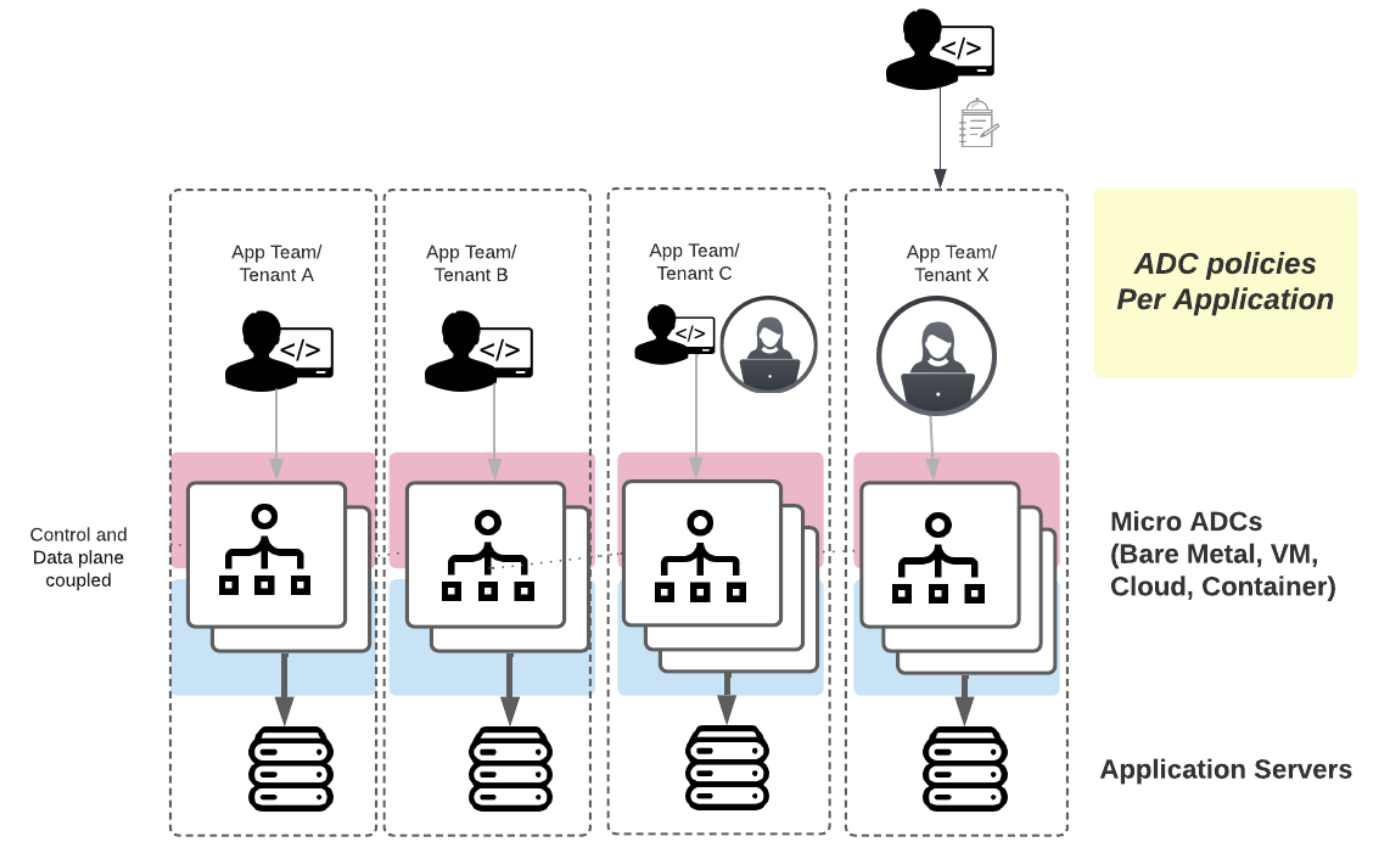
With the widening gap between traditional infrastructure and operations (I&O) and a new application-centric mentality, the ADC industry is now in another stage of evolution. App owners who are witnessing increased demands can no longer wait for the normal change management process; as a result, they choose to use ADC services that are more readily available.
A Micro ADC model or utilizing ADCs per application or ADCs per tenant can solve the problem of concentrating workloads on a single bottleneck or running all ADC configuration changes through a single operations team.
In this model, ADCs are deployed across individually maintained ADC clusters, each dedicated to a specific application, tenant, or customer. Virtualization and cloud computing have made it possible for IT departments to run infrastructure more efficiently and quickly than with expensive and purpose-built hardware appliances clogged with limitations.
The decentralized ADC model reduces bottlenecks and minimizes the blast radius. It allows “right-sizing” of ADCs for each application and empowers application teams to iterate and release new code at their speed - provided they are the owners of their ADC cluster.
An Example of the Micro ADC model:
An ADC cluster for App A may contain more ADC instances running on more powerful Virtual Machine specifications than App B because it necessitates greater system requirements to support heavier workloads. Furthermore, the App Dev team for App B can push new features and modify their ADC policies daily without worrying about affecting App A’s service since they are separate clusters.
In a Micro ADC Model, an App Dev team for one app can push new features and change their ADC policies daily without worrying about impacting another app’s service. Because the clusters are separate, App B’s App Dev team can do so without jeopardizing App A’s service. Furthermore, because App A requires greater system requirements to support heavier workloads, it can be supported by more ADC instances on more powerful Virtual Machine standards than App B - each application is isolated.
What issues doees a Micro ADC model introduce?
It’s easy for things to get horribly out of control if you’ve established a fleet of ADC instances administered by many teams. In the face of dispersed deployments, it would be tough to guarantee compliance, governance, and consistency.
For instance, App A might use an ADC from Vendor X. In contrast, App B (which fails to comply with any security standards) might use the same ADC but a previous version of code that is insecure, or perhaps a different ADC from Vendor Y, and all of sudden you add tool sprawl to the mix too.
Some characteristics of the Micro ADC model
- Modern Software ADCs are lightweight - a footprint of Megabytes, not Gigabytes! Clusters can now be deployed per application - minimizing the problem with a “large blast radius” of a monolithic ADC deployment.
- Virtualization, cloud, and containers make many smaller ADC instances affordable.
- Each ADC cluster can be “right-sized,” vertically sized with adequate CPU, Memory, and powerful enough Networking, OR “right-sized” horizontally in auto-scaling groups to meet peak throughput demands.
Challenges with the Micro ADC model
- A Lack of decoupled control plane makes managing a large fleet of ADCs impractical.
- Each ADC has its control plane, so you risk a drift into inconsistency, out of compliance, and shadow IT.
- In some models, due to organizational governance, Application teams might still be waiting behind service tickets for NetOps teams to execute changes if they are not the ADC owners themselves. therefore back stuck behind service tickets for changes
- In summary, the drawback to this model, if managed without central governance, is the eventual risk of tool sprawl and drifting into inconsistency since there is a lack of a central control plane containing the global policies and standards across all ADC assets
Introducing: LBaaS with a Central Control Plane
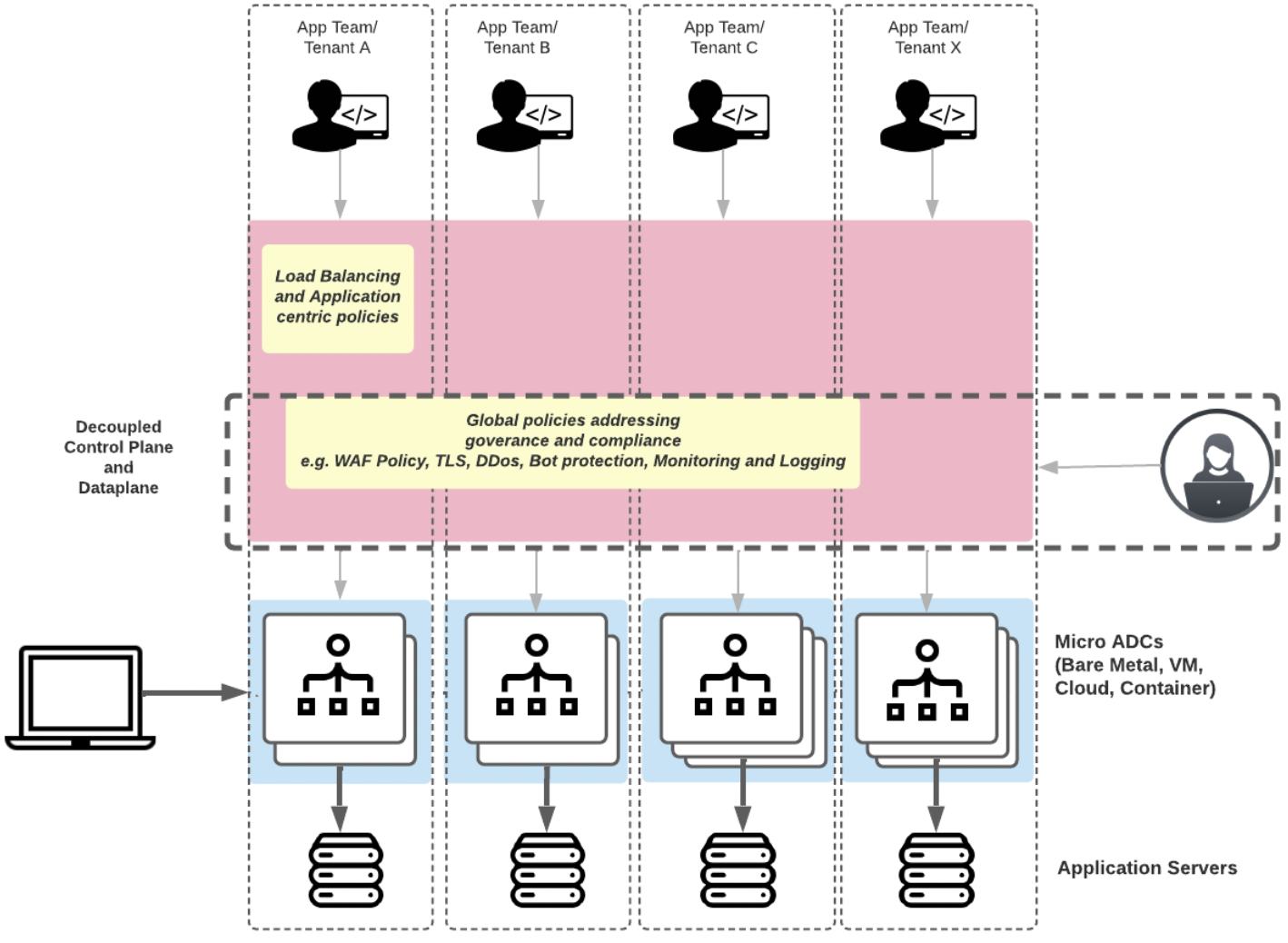
A solution for the enterprise is a centralized control plane for application delivery.
A centralized control plane provides a Load-balancing-as-a-service platform that enables Self-service capabilities for end-users to manage their own ADCs: their load Balancers, Web Applications Firewalls (WAF/WAAP), caches, proxies, and so on, but a “single pane of glass” control plane for operations teams to keeps an inventory of all ADC deployments and enforce mandatory policies such as verbose logging, real-time monitoring, WAF rules, TLS parameters, mandatory DOS or bot protection for governance and compliance.
ADC deployments can continue to be logically organized however makes sense – per application and per tenant if needed. We can have “the best of both worlds” with this arrangement: Platform Operations teams can set “guard rails” or global policies, enabling application developers to manage their per-application ADC deployments and ADC policies.
So in this model, we bring together all the groups involved in the application lifecycle: Network, Security, Application Developers, Site Reliability Engineers, and more. A single platform also simplifies the sprawl of heterogeneous tools and minimizes risk and costs associated with the operating burden and risk exposure.
Characteristics of the modern ADC model:
- Simplicity, ease of use, & footprint are the key drivers (This is best suited for “Typical” ADC services, like “load balancing, and security closer to the apps, like encryption, WAF, bot protection, Layer DOS use cases)
- Due to App services ‘ sprawl, centralized management, orchestration, and analytics are more critical, making the Per-App model manageable.
- Ability to establish core systems integrations and policies for governance and compliance, like WAF Policy, TLS, DOS, BOT protection, logging, and monitoring, then delegate Application control to App teams.
- Applications live in various environments, including microservices. And management across all form factors is uniform and consistent.
Conclusion
So When might you use a centralized control plane for application delivery?
A centralized control plane is a must-have platform when you’re managing massively scalable and distributed apps, with many teams involved in the application lifecycle.
There are a few critical scenarios where you might want to use a centralized control plane:
- You have a hybrid and microservices architecture and need an easy way to manage your application delivery across both environments.
- You have a multi-cloud strategy and reap cost optimization benefits but wish to unify tooling and observability across platforms.
- You have applications distributed on edge compute and need an easy way to consistently manage the high volume of edge nodes.
- You want to speed up app deployment and empower application developers without compromising security.
- You have accumulated a lot of tools and perhaps several control plane solutions to managing subsets of devices.
- You want to extract aggregated insights along with per-app metics
- You want the flexibility of an on-premises or SaaS solution in the central controller
This Post is a unpublished blog post, authored by myself for Snapt