
Load Balancing for Blue-Green, Rolling, and Canary deployment
This article talks about modern deployment and release models and the importance of modern Load Balancers and Application Delivery platforms to support these processes.
Introduction
The most significant difference in software development today compared to the past is the rate of deployments: development teams release software to production earlier and more frequently. Customers want more, and they want it now. However, they are quick to leave you for the competition when things go wrong. According to research, 32% of all customers would desert a company they liked after one bad experience.
Releasing more frequent software updates makes it more likely that deployed code will include errors that negatively affect site reliability and hurt customer happiness. Fortunately, there are strategies to minimize failures in production. Automated and comprehensive testing is essential in the pre-production phases, but a controlled deployment strategy is crucial when releasing new code into live traffic in production.
This article talks about modern deployment and release models and the importance of modern Load Balancers and Application Delivery platforms to support these processes.
Deployment models summary
| Big Bang | Blue-Green | Rolling Release | Canary | |
|---|---|---|---|---|
| Description | An upgrade is done in place of existing code in one go. | New code is released alongside existing code, then traffic is switched to the new version. | New code is released in an incremental roll-out. Old code is phased out as new code takes over. | New code is released to a subset of live users under specific conditions, then an incremental roll-out. |
| Best Suited For | Appliances where no redundancy is available. Monolithic code base tightly coupled with underlying propriety hardware. Offline service during the maintenance window is acceptable. |
Double resource capacity is a non-issue. Live user testing is not critical. Fewer challenges with stateless applications. Instant rollback capability. Fast roll-out preferred. |
Convenient for stateful applications. Apps deployed on a container or cloud platform can be easily orchestrated. |
Slow rollout preferred. Live user testing is essential. Apps deployed on the container or cloud platform can be easily orchestrated. |
| Zero Downtime | No | Yes | Yes | Yes |
| Live User Testing | No | No | Yes | Yes |
| User-Impact On Failures | High | Medium | Low | Low |
| Infrastructure Cost | Low | High | Low | Low |
| Rollback Duration Impact | High | Low | Low | Low |
Frequent releases matter
DevOps practices and modern application infrastructure has made delayed and extended-release cycles a thing of the past. Cloud-native technology and microservices architecture have made this easier; developers may create a modular codebase that allows development teams to write new code and release it independently without affecting other parts of the system.
The advantages of shorter deployment cycles are plenty. To put it simply:
- Accelerated time-to-market: Push new features before the competition.
- Satisfied customers: Customer feedback is implemented faster and drives continuous improvement.
- Improved developer morale: Smaller achievable goals and overall satisfaction.
Deploying without downtime
The goal of most businesses, particularly those with a DevOps culture and an established CI/CD pipeline, is to deploy new features and enhancements without negatively affecting the user experience. You must be able to quickly and securely deploy changes into active production environments without interrupting users engaged in critical activities on your applications.
Deploying new releases without downtime can be achieved by testing in production using rolling releases, including the Canary and Blue-Green deployment methods. Generally, your environment should meet the following requirements to do so:
- A deployment pipeline that can create, test, and deploy to specific environments (Test, Staging, Production).
- A stateless application, so that any nodes in the cluster can serve requests at any time.
- A load balancer to route requests to a high availability cluster of servers nodes (e.g., virtual machines or containers).
Let us dive into deployment strategies but first let’s revisit the classic “Big Bang” deployment methodology.
“Big Bang” Deployment
A “Big Bang” update or upgrade is a method of upgrading an application’s entire or major components in one go. This approach dates back to when all software was usually supplied on physical media and installed by the user.
A Big Bang deployment is high-risk so necessitates an abundance of development and testing, often associated with the “waterfall model.” In theory, it’s simple: you write and test the code, and when it’s ready you release it all at once.
The Big Bang releases are still are around, primarily used in vendor-packaged solutions like desktop applications or dedicated appliances. For web applications, it’s less common as it would require a maintenance window for an extended period - It would be unimaginable for most e-commerce stores to shut down for “just a few hours”.
The following are some of the features of a Big Bang deployment:
- Large and monolithic codebase with tightly coupled software subsystems
- Extensive periods of development and testing
- An intensive upgrade process including planning, maintenance windows, and lots of person-hours – i.e., stress!
- Substantial upgrades that are a significant accumulation of new features, often requiring user-onboarding
- Assume a low probability of failure, given that changes are irreversible or rollbacks are impractical.
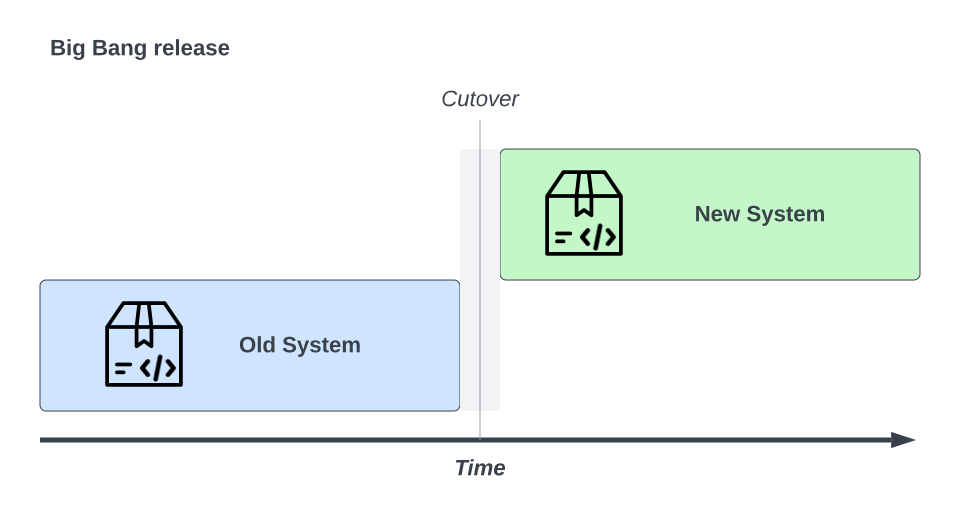
The Big Bang release should be avoided when it comes to online applications. The dangers are too great for public-facing or commercial-critical applications, where outages and performance problems will have a direct and negative financial impact. Similarly, rollbacks are frequently time-consuming, risky, and difficult to execute from a remediation standpoint.
Even with the best of intentions and a robust automated testing suite, there’s always a chance that a particular change could have corner-case bugs, performance issues, or unforeseen consequences once a new release is out in the wild.
With that in mind, let us dive into more modern deployment strategies that overcome the risks of a “Big Bang” failure.
Blue-Green Deployment
While APIs are becoming increasingly popular for sharing data and services, they are getting increasingly complicated, and managing access to these APIs can quickly become a nightmare for API Providers.
One fail-safe method of releasing new application code is to use Blue-Green deployments. In this approach, two production environments operate in tandem. Blue represents the existing “old” code, while Green represents the “new” code.
Blue and Green both run in Production, but initially only Blue receives public traffic.
The new application code is deployed in the Green environment, a replica production environment without any users. Green is thoroughly tested (integration, end-to-end, benchmark tests, etc.) for functionality, performance, and key health indicators in an actual production-ready setting.
When we are happy with the new version, we may route all traffic from the Blue to the Green environment. We can do this gracefully by draining completed sessions from Blue and ramping up new sessions on Green until the Green environment is handling all traffic.
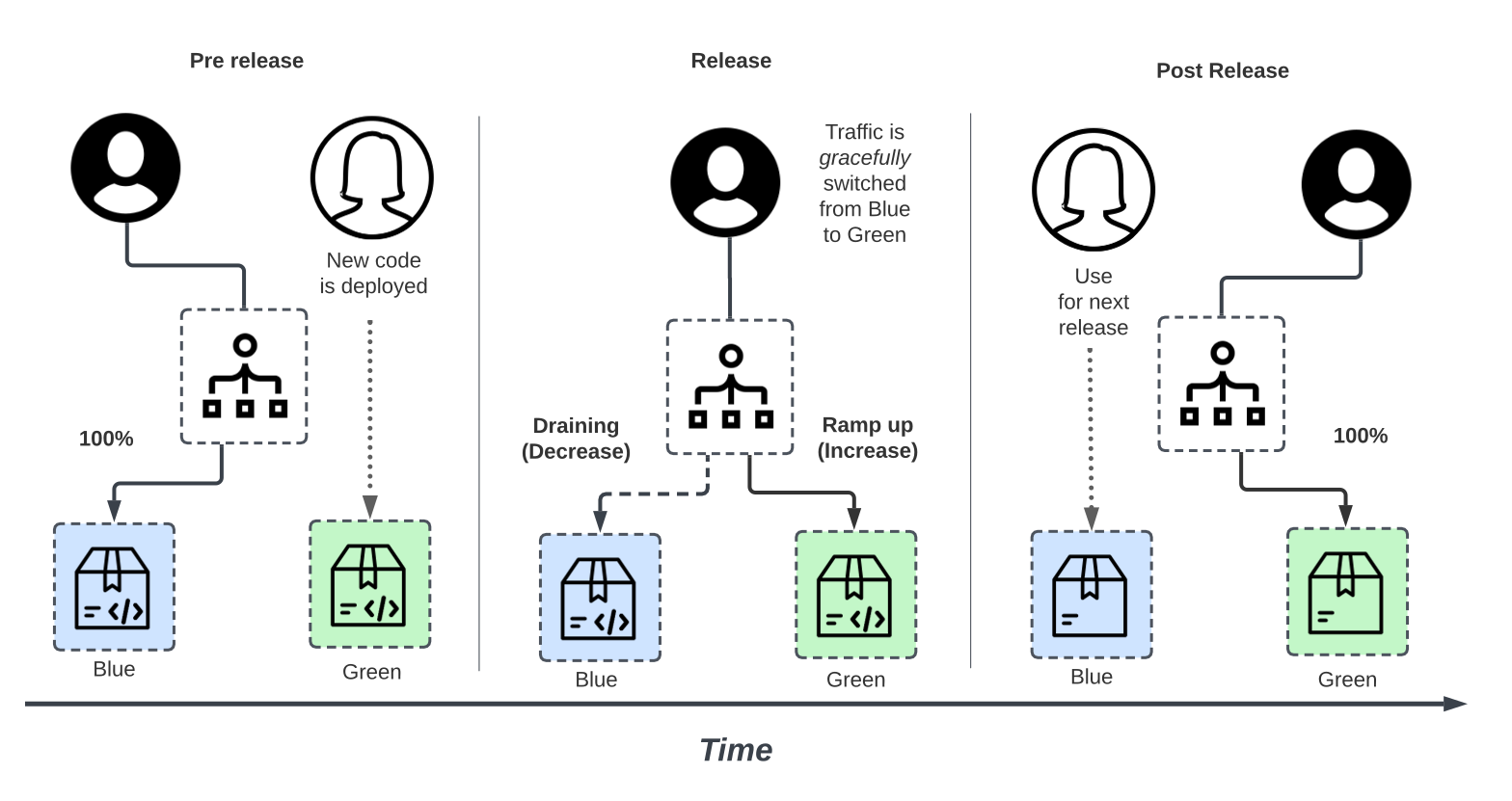
Blue-Green is advantageous because it allows you to revert quickly if something goes wrong. We can “rollback” and reverse traffic routing back to the Blue environment by treating one environment as a hot emergency backup as part of a disaster recovery plan.
Additionally, the Blue environment can be used as a staging environment for your next deployment. Blue and Green environments can cycle between live and previous versions (for rollback), then release the next version. However, more commonly today, with immutable infrastructure and the ability to do Infrastructure-as-Code, previous environments likely get phased out and their infrastructure freed up completely. For new deployments, new virtual machines or containers are provisioned from the ground up with the new codebase “baked in” for the next round of deployment.
The most significant advantage of this technique is that there is no downtime, as the switch is almost instantaneous (which is practically ideal). Users will not notice when their request is served by the new environment since there was no downtime. Unfortunately, this might create difficulties at the same time—if we make an abrupt switchover, all current transactions and sessions would be lost to minimize errors associated with user sessions.
To avoid this, you can use a Load Balancer to drain existing connections on the Blue environment gracefully and ramp up traffic to the new Green environment.
Pros of Blue-Green Deployment
- Low risk of exposing a defective feature to public traffic because we testing the new codebase in the production-like staging environment.
- Rollback is easy because we have a complete set of Production environments.
- Deployment is fast and straightforward compared to other deployment strategies.
Cons of Blue-Green Deployment
- High effort and cost of managing/maintaining two Production environments.
- Real-time analytics and insights are required for rollback decisions.
- Hybrid cloud deployments are not always conducive to “microservice” style deployments. If you have a combination of microservice apps and traditional monolithic applications, coordinating between the two for a Blue-Green deployment might still result in downtime.
- Long-lived transactions in the Blue environment make switching over to Green difficult because you have to wait to close in-flight transactions gracefully.
- Database management might be complex since the two environments are supposed to operate simultaneously (even if they aren’t receiving any traffic).
- Hard to test experimental features to a small audience of live users.
Rolling Deployment or Phased Deployment
Rolling and phased deployment is better suited for online web applications than “Big Bang” releases or a pure Blue-Green deployment approach. It decreases associated risks, such as user-facing downtime without easy rollbacks. In a rolling deployment, an application’s new version gradually takes the place of its old one. The actual deployment happens over time, and new and existing versions coexist without affecting functionality or user experience.
In a rolling deployment strategy, you start by deploying one additional node containing the updated software. For example, this could be a new web application server instance containing code for the new user interface or a new product feature. A load balancer proxying requests to the application is required to route traffic to the new nodes. Over time, you deploy the new version on more nodes. Effectively, you have the latest version of the application running alongside the old one until new nodes have phased out all instances of the old code with the latest version.
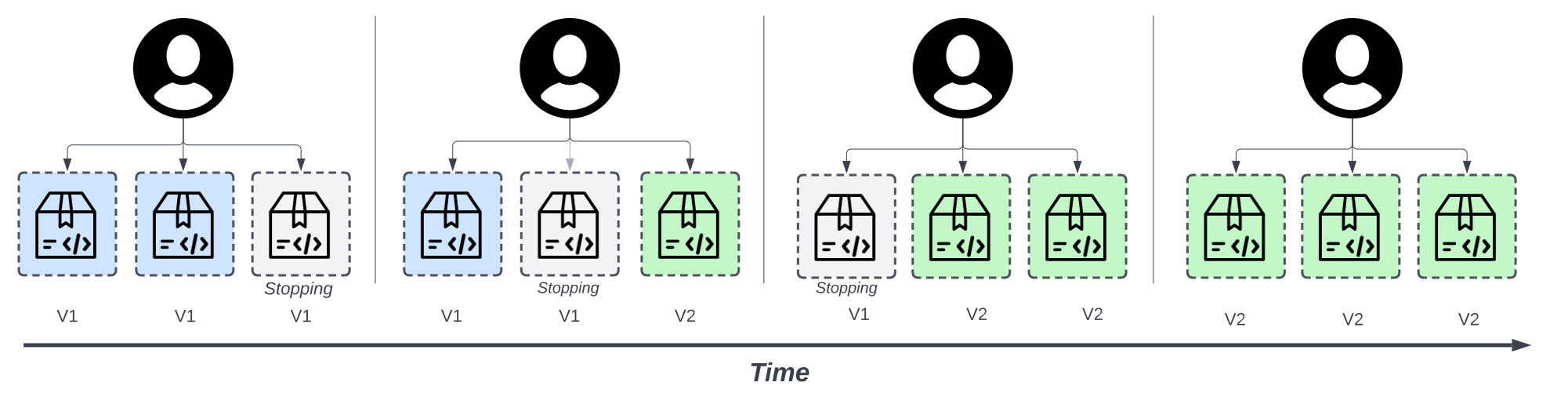
Rolling and phased deployment methods assume replacing instances (e.g., web server nodes) gradually and incrementally. They are easier to implement with modern application infrastructure because autoscaling and rolling deployment orchestration are usually built into the platforms. For example, a container orchestration platform such as Kubernetes will handle containers’ rolling updates. Also, modern applications are typically composed of several components or microservices that may be deployed independently, so a microservice can be released independently of other microservices, further isolating potential issues experienced across the overall application.
You should have real-time monitoring capabilities to track the health of recently added nodes to help with rollback decisions. In the case of errors, you can decide whether to continue the rolling release or rollback instances of the new code deployments to the last known working codebase – this is comparable to the granular level of control a “canary” deployment entails, which we look at next.
Canary Deployment
Canary Deployments, like Rolling Deployments, are a technique for gradually releasing new code. Unlike a Rolling Deployment that releases new code to a limited number of nodes, Canary Deployment controls risk by gradually releasing new code to a segment of users before releasing it to the entire infrastructure and making it available to everyone. This reduces any potential negative impact caused.
The subset of users that get the new code is named the “Canary”, after the canary in the coal mine. The Canary is closely monitored and provides indicators of the health of the new code. This informs decisions on whether to rollback or release the new code to everyone. With Canary deployments, we can isolate key metrics such as errors, latency, and interesting user feedback on the new version.
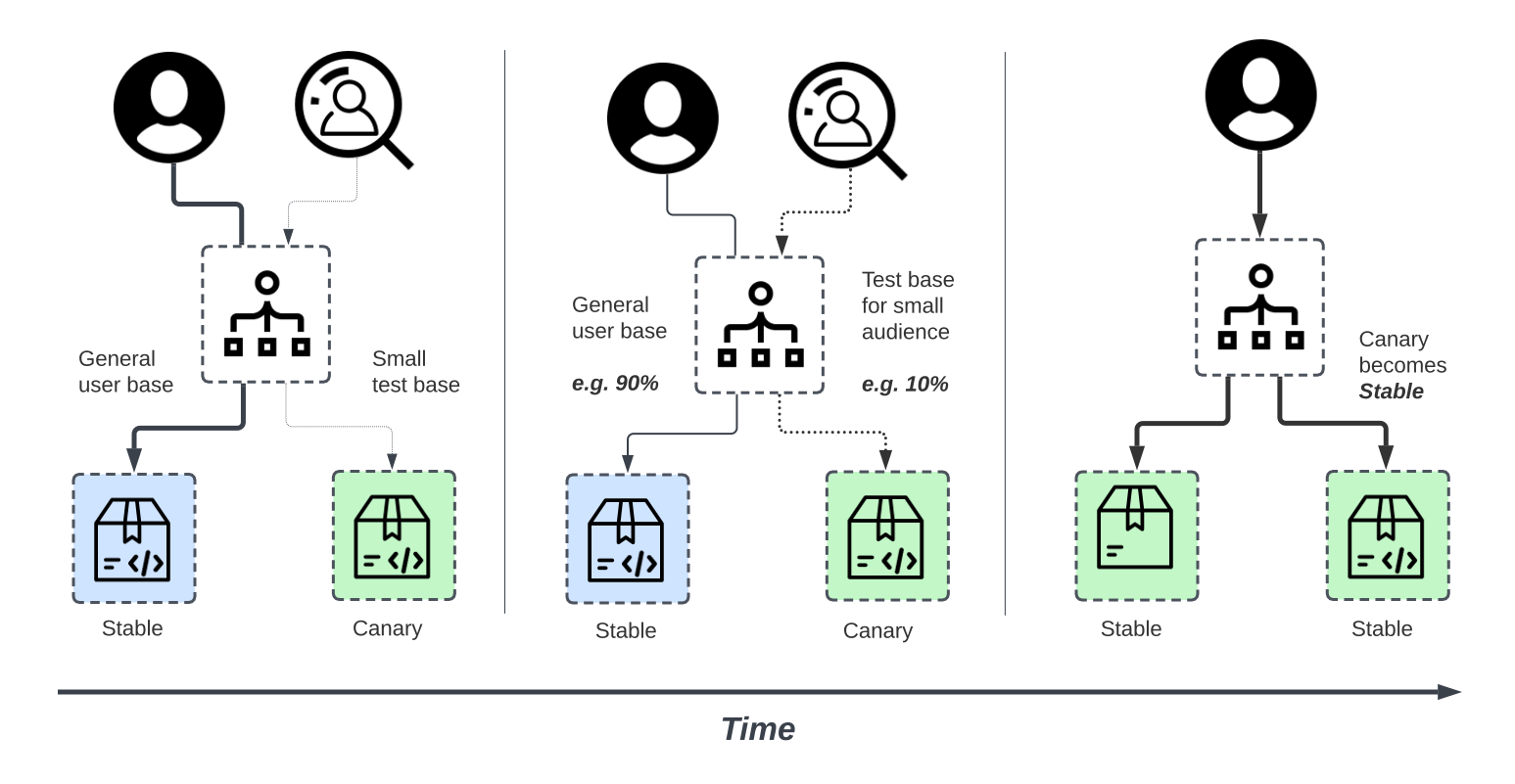
There is no specific formula for dividing traffic, but you may generally expect a Canary release to distribute between 5% and 20% of traffic to the new “Canary” version. A Canary Deployment would never divide traffic 50-50 because if something goes wrong half of the users would have a bad experience.
Pros of Canary Deployment
- Microservices can be updated independently in real-time with the safety of monitoring for performance consistency in live production before a full-scale rollout.
- Least risk for platforms or services handling hundreds of thousands of users each day (gaming, banking, e-commerce, social media, and so on) where a faulty upgrade might result in significant financial losses.
- “Real-world” testing on dynamic client traffic is the best possible test and only feasible on live production servers.
Cons of Canary Deployment
- Traditional infrastructure is static and incurs the expense of maintaining two production environments.
- Real-time analytics and insights are required for rollback decisions.
- Database management might be complex since the two environments are supposed to operate simultaneously (even if they aren’t receiving any traffic).
What About A/B Testing?
As a brief aside, let’s talk about A/B Testing. While A/B testing has many similarities to blue-green testing and canary testing, it differs in several ways. It is also a form of split testing, but the focus is on experimenting rather than reducing errors when introducing a new release.
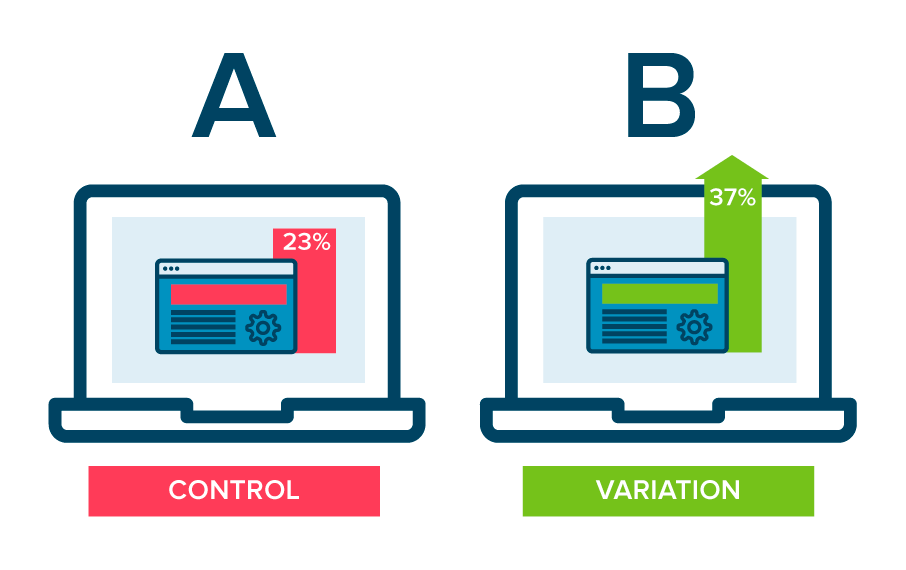
The A/B testing technique involves testing two or more variations of a variable. The A variant is the ‘control’ and the B variant is the ‘variation,’ or a new version of the test variable. The variable tested could be web page layout, new component, etc., and is presented to different segments of visitors simultaneously to see which version has the most significant impact and drives business metrics and user satisfaction.
Another difference between A/B testing and deployment release methods is that the test variant is assumed to operate correctly, with the emphasis on which variant performs best rather than “will it break?. As a result, you may distribute both versions of the application to all users. It might be a 50-50 split, an 80-20 split, or anything in between.
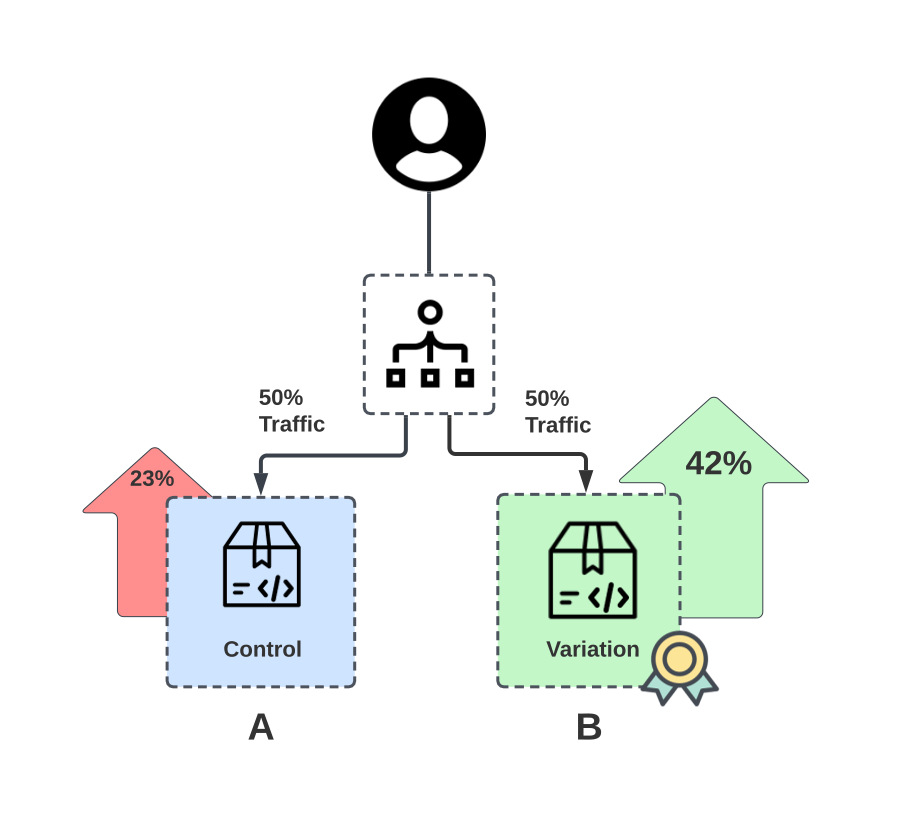
A/B testing eliminates the uncertainty of website optimization and allows the business to make feature releases based on data-backed insights. Metrics that could be of focus include:
- Sales conversions, e.g., the ratio of shopping cart checkouts to abandon
- Post action rating system, e.g. “Rate ease of use out of 5 stars?”
- Average session time and bounce rate
- Advertising click rates
- Registrations
Prerequisites for modern deployments strategies
A load balancer is necessary for traffic splitting between new and existing application codes. However, Plain Old Load Balancing, which focuses on availability and routing to the correct destination, falls short in controlling the traffic distribution and real-time monitoring required for genuinely minimizing errors in Blue-Green and Canary deployments.
An intelligent Load Balancer, or Application Delivery Controller (ADC) if you prefer, is required to execute a live deployment flawlessly, not just to distribute requests but direct them based on a variety of information available from the client, the network, and the environment in which they are operating.
Snapt Nova is an example of modern ADC:
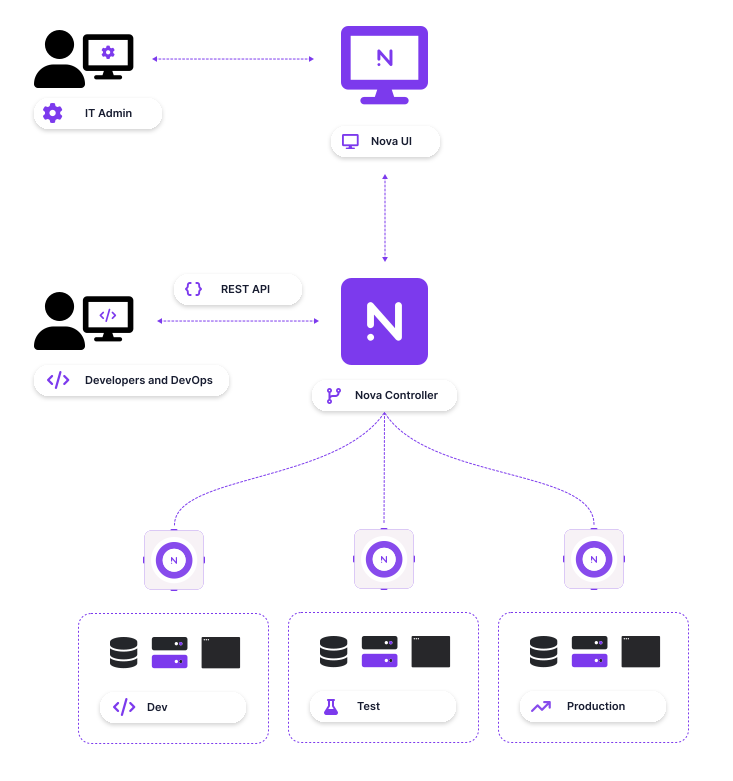
Here are some of the advantages of using a modern application delivery platform such as Snapt to ensure flawless modern deployment strategies.
- Layer 7 intelligence: split traffic based on client attributes - Client identifiers (Name, Loyalty status), Session IDs, device type, Geolocation, and so on.
- Session persistency: first, a routing decision is made, then Session Persistence ensures users don’t bounce between new and old application versions (blue and green).
- Connection draining: the ability to “drain” client connections from an existing node hosting the old application code, completing all sessions before allowing a graceful shutdown of the node. Simultaneously, new nodes take over more traffic and begin handling all client requests in the cluster.
- Fine-grain controls: control traffic distribution instantaneously, increase or decrease routing to new code, or rollback at a flip of a switch or an API call.
- Real-time monitoring and insights: compare Canary and baseline data for precise metrics such as latency, error rates, load averages, and successful requests.
- Global server load balancing (GSLB): provides the ability to extend deployments worldwide, distribute Internet traffic between Blue-Green, and roll out new data centers using Canary deployments.
- Cloud and Platform agnostic: Rolling and Phased Deployments are easier to implement using cloud and container platforms, but most organizations still maintain monolithic apps. To split traffic or migrate between traditional and modern apps, call for a platform-agnostic load balancer to serve as a facade for the hybrid deployment.
- Programmability and APIs: organizations achieve DevOps speed by employing an infrastructure-as-code approach to gain the ability to manage infrastructure through software engineering methods, such as version control and CI/CD. Load Balancers are no exception to modern infrastructure platforms. They should integrate seamlessly into the API-driven architecture of the cloud that allows developers and system administrators to interact with infrastructure programmatically and at scale rather than configuring resources manually.
Conclusion
Whatever deployment strategy you wish to employ for your next application code release, this load balancing use case calls for an advanced application delivery platform. Even more so in a DevOps approach where frequent releases are done and failure is inevitable but planned for.
Modern application teams demand a self-service, API-driven platform that seamlessly integrates into CI/CD pipelines to expedite and safely cut over new application code whether your app is hybrid or microservices.
Snapt Nova is a solution for load balancing and security for modern apps:
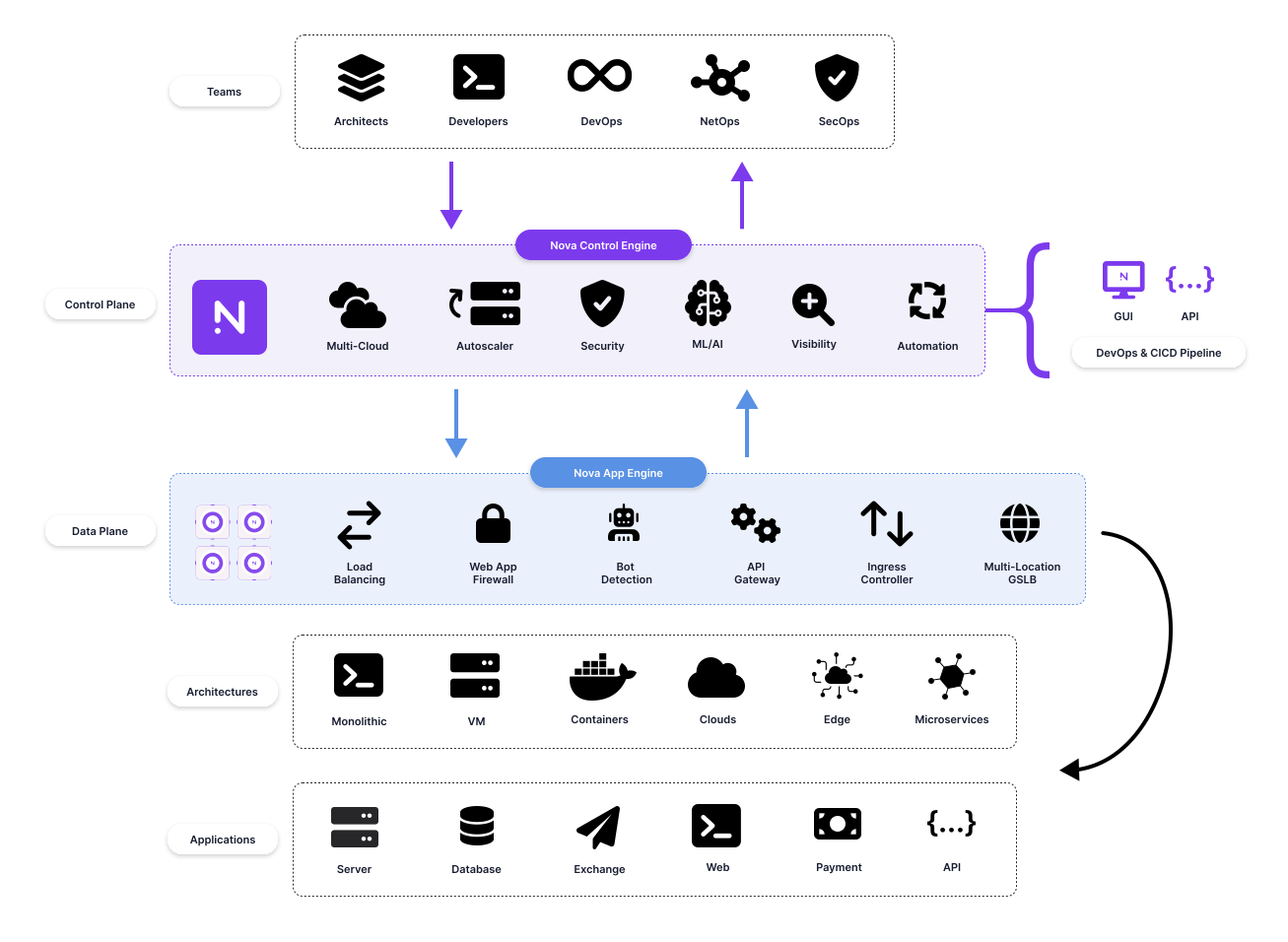
This Post is a re-post by a blog post, authored by myself for Snapt